
流感病毒抗原的持续变异是导致季节性流感反复流行和疫苗需频繁更新的主要原因,对公共卫生防控构成长期挑战。现有基于进化树和突变模型的预测方法,难以系统刻画流感病毒基因组中不同基因片段之间的协同演化规律,预测精度和泛化能力受限。融合生物学结构先验与生成式人工智能的建模方法成为该领域的重要研究方向。
近日,超级计算中心运行与应用服务室联合中国科学院北京基因组研究所(国家生物信息中心)提出了结构感知的DNA语言模型AntigenLM。该模型基于自回归Transformer架构,在预训练阶段直接建模完整流感病毒基因组,显式保留八个基因片段的功能结构与序列顺序信息,以学习跨基因片段的高阶协同进化约束;在微调阶段引入sentinel 标记,引导模型聚焦抗原相关功能区域。实验结果表明,AntigenLM在HA和NA抗原序列预测中的氨基酸错配数较现有模型减少约 50%–70%,在关键表位区域几乎无错配,并在跨地区传播及小样本亚型(如H7N9)场景下保持稳定性能;在流感A多亚型分类任务中取得99.81%的F1分数。该研究验证了生物学结构先验作为归纳偏置融入基础模型设计的有效性。
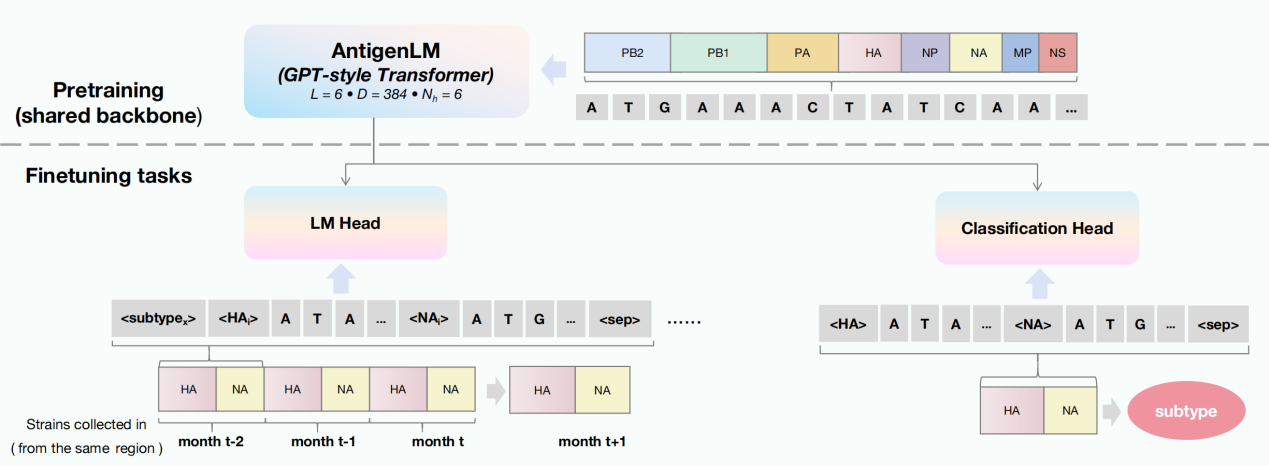
该研究成果已被第14届International Conference on Learning Representations国际学习表征会议(ICLR 2026)录用。ICLR是机器学习与深度学习领域国际顶级会议。我中心博士研究生裴月为论文第一作者,迟学斌研究员为共同通讯作者。该研究成果得到国家重点研发计划项目支持。
相关成果:
Yue Pei, Xuebin Chi, Yu Kang. AntigenLM: Structure-Aware DNA Language Modeling for Influenza. In The Fourteenth International Conference on Learning Representations (ICLR 2026).
责任编辑:郎杨琴