
稀疏矩阵运算在深度学习和科学计算等领域至关重要。但现有的非结构化稀疏数据格式存在复杂的内存访问瓶颈与高昂的格式转换开销等瓶颈,导致当前GPU难以充分释放其硬件性能。
中心人工智能技术与应用发展部门设计了面向GPU CUDA核心的高效稀疏矩阵向量乘算子Acc-SpMV。该研究通过综合考虑矩阵和右端向量,使用矩阵重排、分块、负载均衡和高效内核实现方法有效克服了传统方法中的访存不连续和原子写回冲突等核心瓶颈。实验表明,该算子在性能测试中超越现有的CUDA核心上的主流稀疏矩阵向量乘算子,同时也优于在张量核心上的实现。
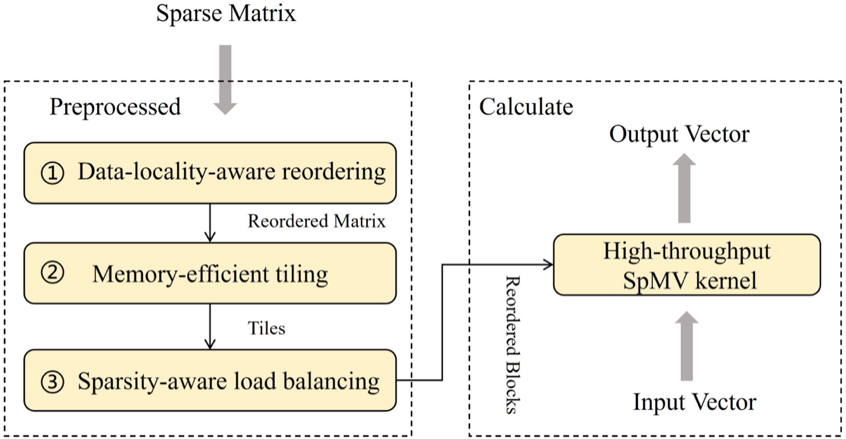
Acc-SpMV 整体设计
针对GPU Tensor核心,设计了高效非结构化稀疏计算框架PillarSparse。该研究通过设计新型稀疏数据格式与高效流水线计算内核,有效克服了传统方法中的多级内存访问和高昂格式转换开销等核心瓶颈。实验表明,在各项算子级别的性能测试中均超越现有的主流稀疏计算库。在端到端图神经网络训练场景中,不仅在全批次任务中取得了显著的加速效果,更能够有效加速实时小批次图采样训练的张量核心解决方案。
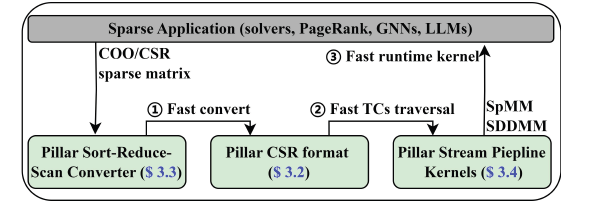
PillarSparse 整体设计
此项研究成果已被国际设计自动化会议Design Automation Conference(DAC 2026,CCF推荐A类会议)录用,该成果得到国家重点研发计划和中国科学院先导专项的支持。前一成果第一作者为中心硕士研究生唐雷,通信作者为我中心研究员周纯葆;后一成果第一作者为中心博士研究生顾峻瑜,通信作者为中心正高级工程师王珏。
相关成果:
[1] Tang Lei, Xin Zhikuang, Wang Zijian, Zhou Chunbao, Wang Jue and Wang Yangang. Acc-SpMV: Accelerating General-purpose Sparse Matrix-Vector Multiplication with GPU CUDA Cores. Proceedings of the 63st ACM/IEEE Design Automation Conference. 2026.
[2] Junyu Gu, Jue Wang, Zhikuang Xin, Zhiqiang Liang, Zongguo Wang, Hongyu Gao, Peng DI and Yangang Wang. PillarSparse: Rethinking Unstructured Sparse Formats for Tensor Cores. Proceedings of the 63st ACM/IEEE Design Automation Conference. 2026.
责任编辑:郎杨琴