
近年来,多模态生成模型快速发展,正在推动多模态内容生成方式变革。
中心先进交互式技术与应用发展部提出智能体驱动的可视分析框架T2VTree,解决多模态生成创作中意图转化难、过程追溯难、结果管理难、素材复用难等问题。该框架将用户意图、提示词、参数、生成结果等抽象为可编辑回溯的创作节点,实现了生成内容的人智协同交互控制。基于该框架研发的T2VTreeVA系统相比当前先进的ComfyUI工作流,视频创作周期减少82.9%,模型调用次数减少37.2%,可复用内容由4.3个提升至8.3个,显著提升了多模态生成创作的过程可控性、探索效率和结果复用能力。
该成果已被PacificVis 2026录用,PacificVis是CCF推荐C类会议。论文第一作者为我中心硕士研究生郑卓云,董禹助理研究员为共同第一作者,通讯作者为单桂华研究员。该工作得到中国科学院-湖南省文化和科技融合联合攻关项目(2024JK4002)与中心基础研究基金青年项目(25YF08)支持。
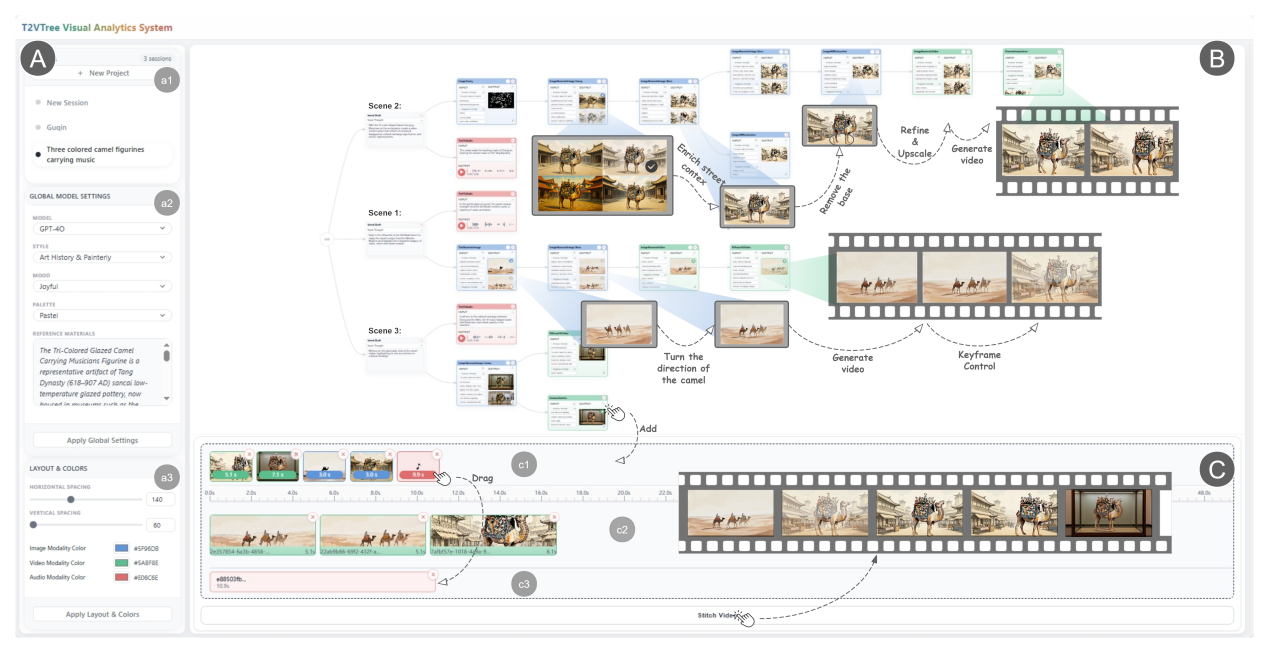
智能体驱动的多模态模型生成可视分析系统T2VTreeVA
相关成果:Zhuoyun Zheng, Yu Dong, Gaorong Liang, Guan Li, Guihua Shan*, Shiyu Cheng, Dong Tian, Jianlong Zhou, and Jie Liang. "T2VTree: User-Centered Visual Analytics for Agent-Assisted Thought-to-Video Authoring." In 2026 IEEE 19th Pacific Visualization Conference (PacificVis), pp. 369-379. IEEE, 2026.
责任编辑:郎杨琴